We're happy to announce the release of RelStorage 3.0, the relational storage engine for ZODB. Compared to RelStorage 2, highlights include a 30% reduction in memory usage, and up to 98% faster performance! (Ok, yes, that's from one specific benchmark and not everything is 98% faster, but improved performance was a major goal.)
RelStorage 3.0 is a major release of RelStorage with a focus on performance and scalability. It's the result of a concentrated development effort spanning six months, with each pre-release being in production usage with large databases.
Read on to find out what's new.
Contents
Overview
Please note that this document is only an overview. For details on the extensive changes since the previous release, RelStorage 2.1, and this one, please view the detailed changelog.
If you're not familiar with ZODB (the native Python object database) and how it uses pluggable storage engines like RelStorage, please take a moment to review this introduction.
This document will cover a few important things to know about RelStorage 3.0, and then go over some of the most important changes in it. Next, we'll show how those changes affect performance. Finally, we'll wrap it up with a whirlwind tour of some of the minor changes.
Backwards Incompatible Changes
Before we get to the good stuff, it's important to highlight the small number of backwards incompatible changes and other things to be aware of when migrating from RelStorage 2 to RelStorage 3.
Schema Changes
In history preserving schemas, the empty column of the transaction table has been renamed to is_empty. In MySQL 8.0.4, empty became a reserved word. The table is altered automatically when first opened with RelStorage 3.0. This makes the schema incompatible with opening under RelStorage 2. [1]
A new table, used during the commit process, is also automatically added when first opened with RelStorage 3.
Under MySQL, any remaining tables that were using the MyISAM engine are converted to InnoDB when the schema is first opened. The only tables remaining that were MyISAM were the pack tables and the new_oid table, all of which should ordinarily be empty, so this conversion shouldn't take long.
Option Changes
The shared-blob-dir default has changed from true to false. If you were using a non-shared blob-dir, meaning that blobs were only stored on the filesystem, you'll need to explicitly set this to true. The previous default could easily lead to accidental data loss, and there is now a performance penalty for a true value. See blob_cache for more information.
The previously deprecated option poll-interval has been removed.
Several of the cache persistence options are now deprecated and ignored. They'll generate a warning on startup if found in the configuration.
Concurrent Deployment With RelStorage 2 Is Not Possible
Caution!
It is not possible for RelStorage 3 to write to a database at the same time that RelStorage 2 is writing to it.
The specifics around locking have changed entirely, and are not compatible between the two versions. If RelStorage 3 and RelStorage 2 are both writing to a database, corruption is the very likely result. For this reason, shutting down all RelStorage 2 instances, or at least placing them into read-only mode, is required.
RelStorage does not take specific steps to prevent this. It is up to you to ensure any RelStorage 2 instances are shutdown or at least read-only before deploying RelStorage 3.
Major Changes
Benchmarking Notes
The benchmark data was collected with zodbshootout 0.8. Recent revisions of zodbshootout have adopted pyperf as the underlying benchamrk engine. This helps ensure much more stable, consistent results. It also allows collecting a richer set of data for later analysis. The data was passed through the seaborn statistical visualization library, which is built using pandas, numpy and matplotlib, to produce the plots shown here.
For the comparisons between RelStorage 3 and RelStorage 2, the RDBMS servers (MySQL 8 and PostgreSQL 11) were run on one computer running Gentoo Linux using SSD storage. The RelStorage client was run on a different computer, and the two were connected with gigabit ethernet. The machines were otherwise idle.
The comparisons used Python 2.7.16 (because 2.7 was the only version of Python that had a native code gevent driver compatible with RelStorage 2). The database drivers were mysqlclient 1.4.4 and psycopg2 2.8.4. The gevent driver used this version of ultramysql, umysqldb 1.0.4.dev2, PyMySQL 0.9.3 and gevent 1.5a2.
Why transaction of size 1, 5 and 20 objects? Review of a database containing 60 million objects showed the average transaction involved 2.6 objects with a standard deviation of 7.4. A database with 30 million objects had an average transaction of 6.1 objects and a standard deviation of 13.
In all the examples that follow, results for PostgreSQL are green while those for MySQL are in blue. The darker shades are RelStorage 3, while the lighter shades are RelStorage 2. The y axis is time, and shorter bars are better (no units or tickmarks are shown because the scale differs between graphs and we're generally focused on deltas not absolute values); the black line that appears in the middle of some bars is the confidence interval. Click for a larger version.
Most examples show a cross section of RDBMS server by concurrency kind (threads or process) by concurrency level (1, 5, or 20 concurrent threads or processes) by object count (1, 5 or 20 objects).
To accomplish its goals of improving performance (especially under high loads distributed across many processes on many machines), reducing memory usage, and being usable in small environments without access to a full RDBMS server (such as containers or test environments), RelStorage features several major internal changes.
Pickle Cache
The shared in-memory pickle cache has been redesigned to be precise and MVCC based; it no longer uses the old checkpoint system. This means that old revisions of objects can proactively be removed from the cache when they are no longer needed. Together, this means that connections within a process are able to share polling information, with the upshot being that there are no longer large, stop-the-world poll queries in order to rebuild checkpoints. Individual poll queries are usually smaller too.
It has also been changed to have substantially less overhead for each cached object value. Previously, it would take almost 400 bytes of overhead to store one cache entry. In examining a database of 60 million objects, it turned out that the average object size was only a little over 200 bytes. Using 400 bytes to store 200 bytes was embarrassing, and because the cache limit computations didn't take the overhead into account it meant that if you configured an in-memory cache size of 200MB, the cache could actually occupy up to 600MB.
Now, storing a cached value needs only a little more than 100 bytes, and the exact amount of overhead is included when enforcing the cache limit (so a 200MB limit means 200MB of memory usage). The Python cache implementation using a CFFI-based Segmented LRU and Python lookup dictionary were replaced with a minimal Cython extension using a C++ boost.intrusive list and map. This also essentially eliminates the cache's impact on the Python garbage collector, which should improve garbage collection times [2].
In concrete terms, one set of production processes that required almost 19GB of memory now requires only about 12GB: a 36% reduction.
Persistent Cache
Along with rearchitecting the in-memory cache, the on-disk persistent cache has been rebuilt on top of SQLite. Its hit rate is much improved and can easily reach 100% if nothing in the database changed. If you haven't deployed the persistent cache before, now would be a great time to give it a try.
If you had used the persistent cache in the past, the new cache should just work. Old cache files will be ignored and you might want to manually remove any that exist to reclaim disk space.
ZODB 5 Parallel Commit
RelStorage 3 now requires ZODB 5, and implements ZODB 5's parallel commit feature. During most of the ZODB commit process, including conflict resolution, only objects being modified are exclusively locked. Objects that were provided to Connection.readCurrent() are locked only in share mode so they may be locked that way by several transactions at the same time. (This fact is particularly important because BTrees call readCurrent() for every node traversed while searching for the correct leaf node to add/remove/update, meaning there can be a surprising amount of contention.)
Only at the very end of the ZODB commit process when it is time to commit to the database server is a database-wide lock taken while the transaction ID is allocated. This should be a very brief time, so transactions that are operating on distinct sets of objects can continue concurrently for much longer (especially if conflicts occur that must be resolved; one thread resolving conflicts no longer prevents other threads from resolving non-overlapping conflicts).
This works on most databases, but it works best on a database that supports NOWAIT share locks, like MySQL 8 or PostgreSQL. SQLite doesn't support object-level locking or parallel commit. Oracle doesn't support shared object-level locks.
ZODB 5 Prefetch
RelStorage 3 implements efficient object prefetching through Connection.prefetch(). This is up to 74% faster than reading objects individually on demand.

RelStorage 2 did not implement prefetch so this benchmark falls back to reading objects individually. RelStorage 3 is able to query the database in a single bulk operation.
Support for SQLite
Note
The SQLite support is relatively new and hasn't received much production-level testing.
On some systems, the underlying sqlite3 module may experience crashes when lots of threads are used (even though a ZODB connection and its RelStorage instance and sqlite connection are not thread safe and must only ever be used from a single thread at a time, the sequential use from multiple threads can still cause issues).
RelStorage 3 can use a local SQLite3 database file. I'll quote the RelStorage FAQ to explain why:
Why does RelStorage support a SQLite backend? Doesn't that defeat the point?
The SQLite backend fills a gap between FileStorage and an external RDBMS server.
FileStorage is fast, requires few resources, and has no external dependencies. This makes it well suited to small applications, embedded applications, or applications where resources are constrained or ease of deployment is important (for example, in containers).
However, a FileStorage can only be opened by one process at a time. Within that process, as soon as a thread begins committing, other threads are locked out of committing.
An external RDBMS server (e.g., PostgreSQL) is fast, flexible and provides lots of options for managing backups and replications and performance. It can be used concurrently by many clients on many machines, any number of which can be committing in parallel. But that flexibility comes with a cost: it must be setup and managed. Sometimes running additional processes complicates deployment scenarios or is undesirable (for example, in containers).
A SQLite database combines the low resource usage and deployment simplicity of FileStorage with the ability for many processes to read from and write to the database concurrently. Plus, it's typically faster than ZEO. The tradeoff: all processes using the database must be on a single machine on order to share memory.
I'll leave the rest to the FAQ, with the exception of these two performance graphs showing SQLite slot in comfortably next to FileStorage and ZEO.

For small to medium sized write transactions, SQLite can actually outperform FileStorage and ZEO when threads are in use. When separate processes are in use, SQLite always beats ZEO.
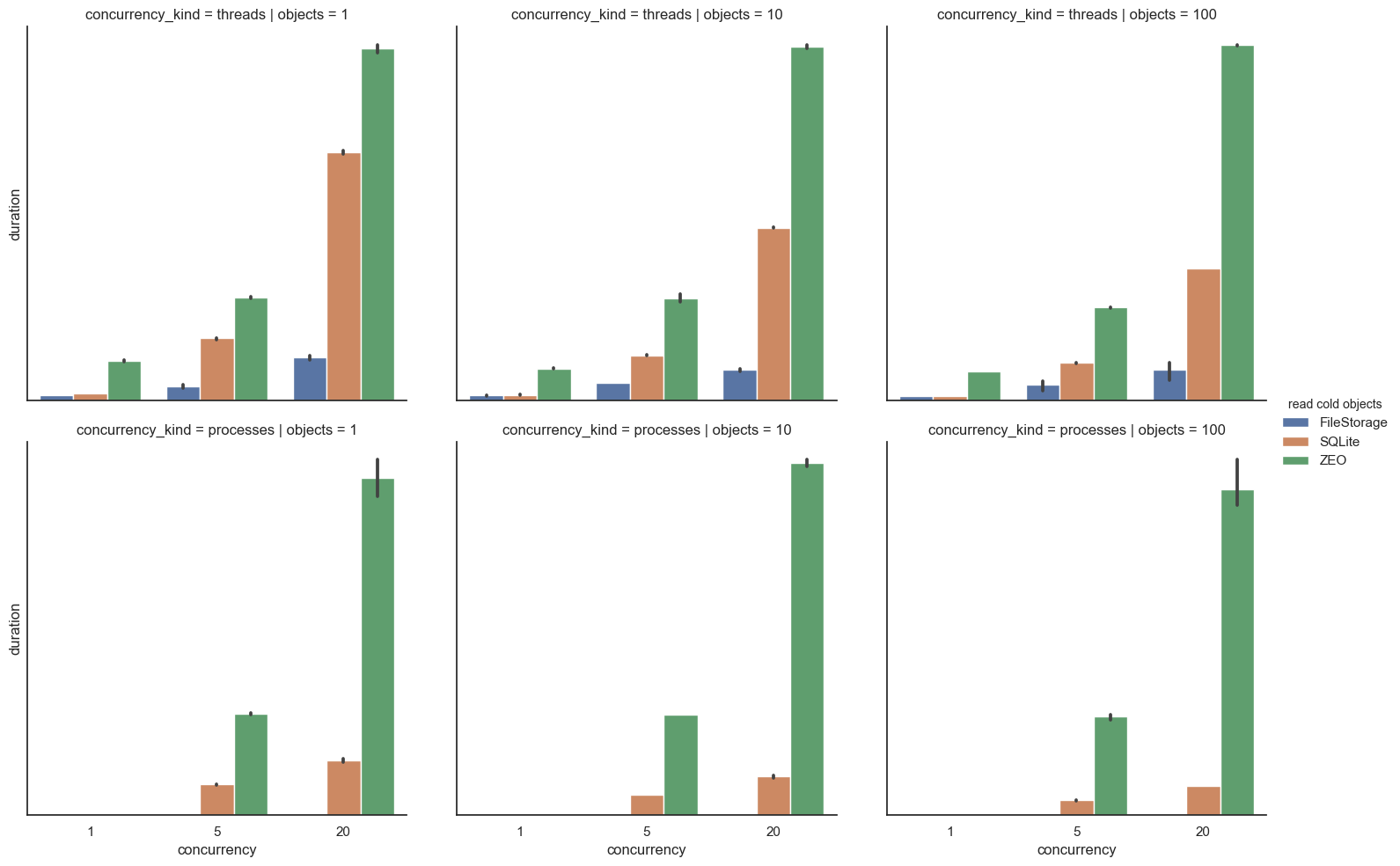
When reading objects, SQLite is always faster than ZEO, but slower than FileStorage.
Performance Improvements
Much effort was spent on improving RelStorage's performance, in terms of overall speed and memory usage as well as concurrency and scalability. Here, let's compare the performance of RelStorage 2.1.1 with RelStorage 3.0 graphically from a speed perspective.
Writing
Note
RelStorage 2 failed to complete a number of the write benchmarks that used 20 objects and 20 concurrent processes or threads: some tasks would fail to obtain the commit lock using the default 10 second timeout. Those tasks were excluded from the results.
RelStorage 3 did not have this problem.
We'll start with writing to the database:
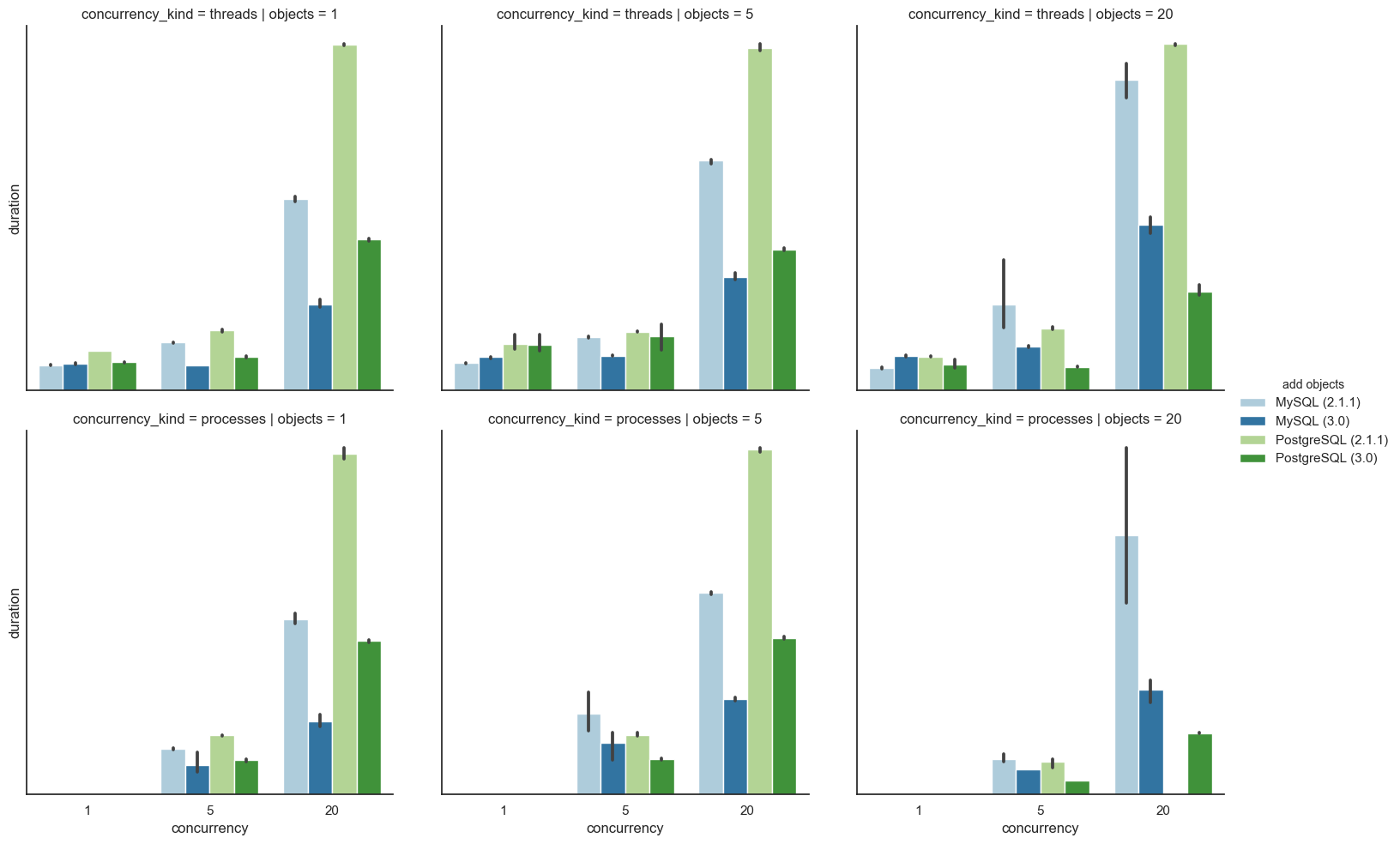
When simply adding new objects to the database, PostgreSQL is between 29% and 72% faster. MySQL is essentially within the margin of error for the non-concurrent cases, and up to 79% faster for larger, more concurrent tests.
Updating existing objects:
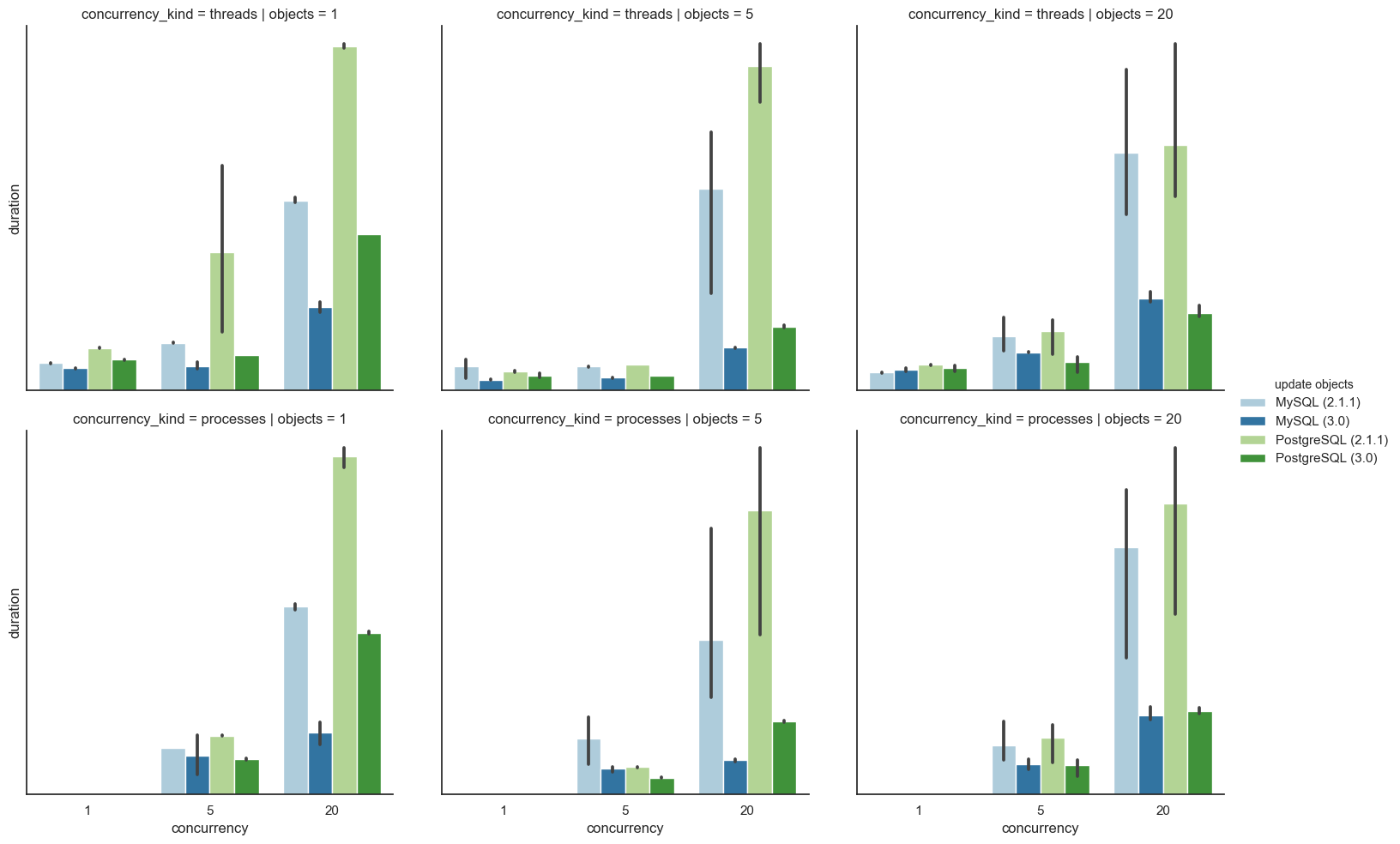
When updating objects that already existed in the database, The difference for MySQL ranges between statistically insignificant up to to 79% faster.. PostgreSQL likewise ranges from statistical insignificance and up to 80% faster.
Handling conflicts received extra attention.

Updating objects that have to resolve conflicts.
Once again, some cases were statistically insignificant for both databases. The cases that were statistically significant show a 15% to 84% improvement for PostgreSQL, with the range being from 11% to 89% for MySQL. Not only is it faster, going by the much tighter confidence intervals, it's also less volatile and more consistent.
Reading
RelStorage, like ZEO, includes a secondary pickle cache that's shared amongst all the connections in a process. Here's what it looks like to read data out of that cache (not hitting the database at all).

Reading from the pickle cache, by concurrency kind and object count.
Because the bottom row of graphs is separate processes, they don't benefit much from the actual sharing of the cache. The improvements there, 30 – 40%, show the effect of the cache changes in isolation. The top row of graphs shows the improvement in the intended use case, when the cache is shared by multiple threads in a process. In that case, the difference can be up to 90%. [5]
Reading directly from the database, on the other hand, is harder to qualify.

Oh no! It looks like RelStorage 3 actually got slower when reading directly from the database. That's one of its core tasks. How could that be allowed to happen? (Spoiler alert: it didn't.)
Look closely at the pattern. In the top row, when we're testing with threads, RelStorage 3 is always at least as good as RelStorage 2 and frequently better [4]. It's only the bottom row, dealing with processes, that RelStorage 3 looks bad. But as you move further to the right, where more processes are making more queries to load more objects, the gap begins to close. At 20 objects in 5 processes, the gap is essentially gone. (And then we fall off a cliff at 20 processes querying 20 objects. It's not entirely clear exactly what's going on, but that's more CPUs/hardware threads than either the client machine or server machine has so it's not surprising that efficiency begins to fall.)
It turns out the benchmark includes the cost of opening a ZODB connection. For processes, that's a connection using a whole new ZODB instance, so there will be no prior connections open. But for threads, the ZODB instance is shared, so there will be other connections in the pool.
Working with brand new RelStorage connections got a bit slower in RelStorage 3 compared to RelStorage 2. They use more prepared statements (especially on PostgreSQL), and they use more database session state (especially on MySQL). Performing the first poll of the database state may also be a bit more expensive. So when the connection doesn't get used to do much before being closed, these costs outweigh the other speedups in RelStorage 3. But somewhere between making 5 and 20 queries for objects, the upfront costs are essentially amortized away. As always in ZODB, connection pooling with appropriate pool settings is important.
gevent
In RelStorage 2, gevent was supported on Python 2 and Python 3 for MySQL and PostgreSQL when using a pure-Python database driver (typically PyMySQL for the former and pg8000 for the later). There was special gevent support for MySQL using a custom database driver, but only on Python 2. This driver took a hybrid approach, providing some C acceleration of low-level operations, but delegating most operations to PyMySQL.
RelStorage 3 supports gevent-aware, fully native drivers, for both PostgreSQL and MySQL on both Python 2 and Python 3. Moreover, the MySQL driver has special support for RelStorage's two-phase commit protocol, essentially boosting the priority of a greenlet that's committing [6]. This avoid situations where a greenlet takes database-wide locks and then yields control to a different greenlet that starves the event loop, leaving the database locked for an unacceptable amount of time and halting the forward progress of other processes.
Do these things make a difference? We can compare the performance of gevent with MySQL to find out.
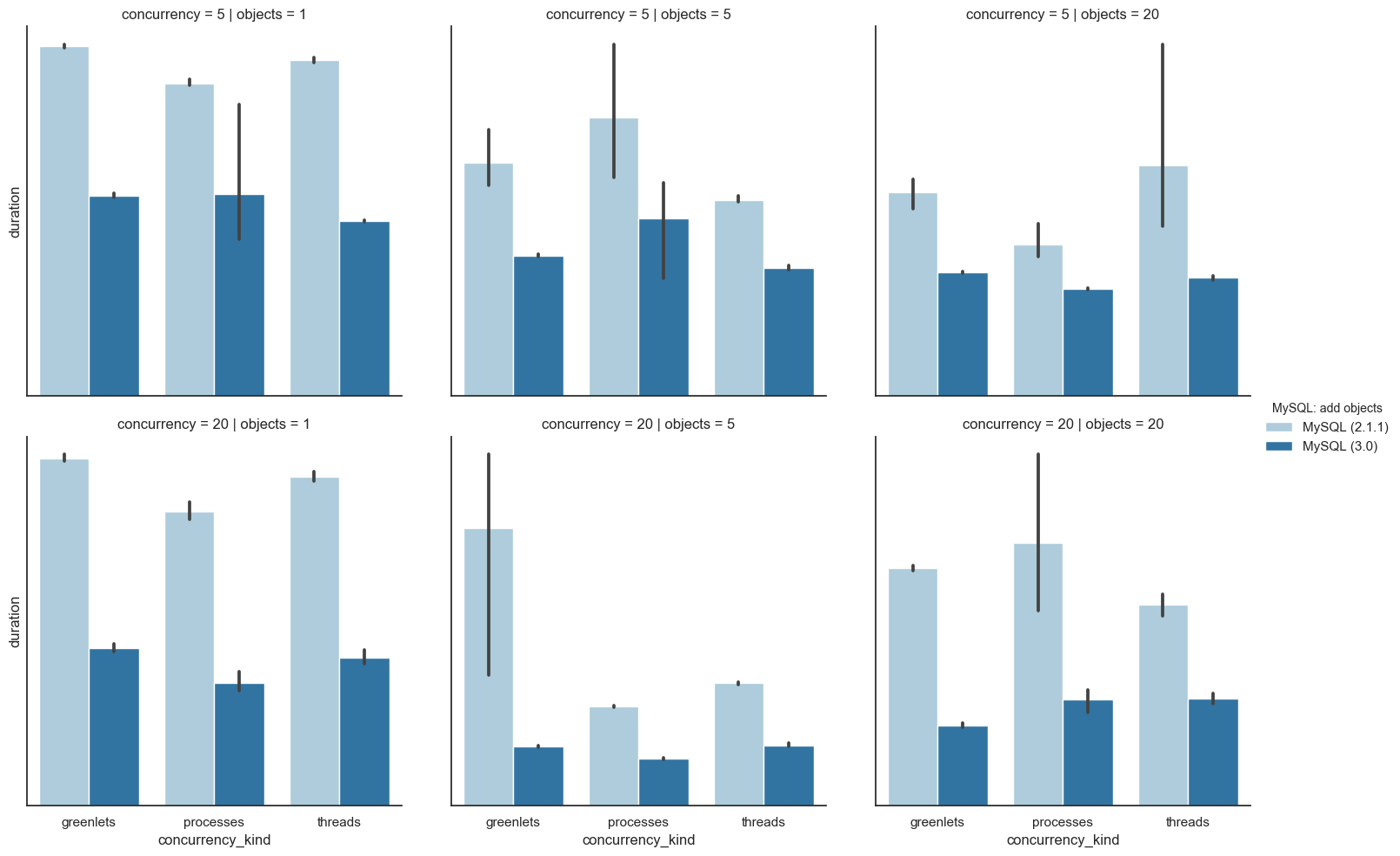
Adding objects, by concurrency type.
Adding objects improved across the board for all concurrency types.

Updating objects, by concurrency type.
Updating objects improved across the board for all concurrency types. Updating conflicting objects shows a similar gain.

Reading objects, by concurrency type.
Reading individual objects, by contrast, shows no distinct trend. I suspect that it's essentially unchanged (the transactional and polling parts around it that were changed are not measured here), but we'd need more samples to be able to properly show that.
Minor Changes
This section documents some of the other changes in RelStorage 3.
Supported Versions
Support for PostgreSQL 12 and MySQL 8 were added, as well as support for Python 3.8.
Support for MySQL 5.6 and PostgreSQL 9.5 were removed, as was support for old versions of ZODB. Also, RelStorage no longer depends on ZEO (so it's theoretically possible that Python 2.7.8 and earlier could run RelStorage, but this isn't tested or recommended).
Most tested database drivers were updated to newer versions, and in some cases the minimum supported versions were updated.
- mysqlclient must be 1.4, up from 1.3.7.
- psycopg2 must be 2.8, up from 1.6.1.
- psycopg2cffi must be 2.8.1, up from 2.7.4.
- cx_Oracle must be 6.0, up from 5.0.
- Support was removed for the Python 2-only driver umysqldb.
This table summarizes the support various databases have for RelStorage 3 features.
| PostgreSQL | MySQL | Oracle | SQLite | |
|---|---|---|---|---|
| Parallel commit | Yes | Yes | Yes | No |
| Shared readCurrent locks | Yes | Yes | No | No |
| Non-blocking readCurrent locks | Yes | Native on MySQL 8, emulated on MySQL 5.7 | Yes | N/A (there is no distinction in lock type) |
| Streaming blobs | Yes | No (emulated via chunking) | Yes | No (consider configuring a shared-blob-dir) |
| Central transaction ID allocation | Yes | Yes | No (could probably be implemented) | N/A (but essentially yes because it only involves one machine) |
| Atomic lock and commit without Python involvement | Yes (except with PG8000) | Yes | No (could probably be implemented) | No |
The Blob Cache
Using a shared-blob-dir (where all blobs are only stored on a filesystem and never in the database) disables much of the parallel commit features. This is because testing whether we can actually store the blob successfully during the "vote" phase of ZODB's two-phase commit requires knowing the transaction ID, and knowing the transaction ID requires taking the database-wide commit lock. This is much sooner than is otherwise required and the lock is held for much longer (e.g., during conflict resolution).
Increasing popularity, and ever-growing databases, make the implementation of the blob cache all the more important. This release focused on blob cache maintenance, specifically the process whereby the blob-cache-size (if any) is ensured.
First, for history free databases, when a new revision of a blob is uploaded to replace an older one, if RelStorage has the old revision cached on disk and can determine that it's not in use, it will be deleted as part of the commit process. This applies whether or not a cache size limit is in place.
If it becomes necessary to prune the blob cache, the process of doing so has been streamlined. It spawns far fewer unnecessary threads than it used to. If the process is using gevent, it uses an actual native thread to do the disk scan and IO instead of a greenlet, which would have blocked the event loop.
Finally, if running the pruning process is still too expensive and the thread interferes with the work of the process, there's a new option that spawns a separate process to do the cleanup. This can also be used manually to perform a cleanup without opening a storage.
Packing and GC
History-preserving databases now support zc.zodbdgc for multi-database garbage collection.
RelStorage's native packing is now safer for concurrent use in history-free databases thanks to correcting several race conditions.
For both types of databases, packing and pre-packing require substantially less memory. Pre-packing a large database was measured to use 9 times less memory on CPython 3 and 15 times less on CPython 2 (from 3GB to 200 MB).
Performance Grab Bag
Here's a miscellaneous selection of interesting changes, mostly performance related.
-
Reduce the number of network communications with the database.
RelStorage tries harder to avoid talking to the database more times than necessary. Each round-trip introduces extra latency that was measurable, even on fast connections. Also, native database drivers usually release the GIL during a database operation, so there could be extra overhead introduced acquiring it again. And under gevent, making a query yields to the event loop, which is good, but it could be an arbitrary amount of time before the greenlet regains control to process the response. If locks are being held, too many queries could spell disaster.
This was accomplished in several ways. One way was to move larger sequences of commands into stored procedures (MySQL and PostgreSQL only). For example, previously to finish committing a transaction, RelStorage required 7 database interactions in a history-preserving database: 1 to acquire the lock, 1 to get the previous transaction id, 1 to store transaction metadata, 1 to store objects, 1 to store blobs, 1 to update the current object pointers, and finally one to commit. Now, that's all handled by a single stored procedure using one database operation. The Python process doesn't need to acquire the GIL (or cycle through the event loop) to commit and release locks, that happens immediately on the database server regardless of how responsive the Python process is.
More careful control of transactions eliminated several superflous COMMIT or ROLLBACK queries in all databases. Similarly, more careful tracking of allocated object identifiers (_p_oid) eliminated some unnecessary database updates.
The use of upserts, which eliminate at least one query, was previously limited to a select few places for PostgreSQL and MySQL. That has been extended to more places for all supported databases.
-
Allocate transaction IDs on the database server.
This was primarily about reducing database communications. However, because transaction IDs are based on the current time, it also has the important side-effect of ensuring that they're more consistently meaningful with only one clock to consider.
Previously, all transaction IDs could be at least as inaccurate as the least-accurate clock writing to the database (if that clock was in the future).
-
PostgreSQL uses the COPY command to upload data.
Specifically, it uses the binary format of the bulk-loading COPY command to stream data to the server. This can improve storage times by 20% or so.
Conclusion
RelStorage 3 represents a substantial change from RelStorage 2. The pickle cache—both in-memory and on-disk—has been completely rewritten, the locking process has been re-imagined in support of parallel commit, time-sensitive logic moved into stored procedures, and more. Despite that, it should be a drop-in replacement in most situations.
Although RelStorage 3 has been in production usage under heavy load at NextThought for its entire development cycle, and we haven't encountered any problems with it that could lead to data loss, it's still software, and all software has bugs. Please exercise appropriate care when upgrading. Bug reports and pull requests are encouraged and appreciated.
We're very happy with the enhancements, especially around performance, and hope those improvements are applicable to most users. We welcome feedback on whether they are or are not, and also want to hear about where else RelStorage could improve.
Finally, I'd like to say thank you to everyone who has contributed to the development of RelStorage 3, whether through testing pre-releases, filing bug reports, or sharing enhancement ideas and use cases. It's greatly appreciated.
Footnotes
| [1] | Why not simply "quote" the reserved word? Much of the SQL queries that RelStorage uses are shared among all supported databases. By default, MySQL uses a different, non-standard quoting syntax that wouldn't work with the other databases. That can be changed by altering the SQL Mode, but I was trying to avoid having to do that. In the end it turned out that another change [3] forced the alteration of the mode, so I should have just done that in the first place. But since there are good reasons to prevent RelStorage 2 and 3 from ever trying to use the same database, the incompatibility didn't seem like a big deal. |
| [2] | In CPython, the generational (cyclic) garbage collector uses time proportional to the number of objects in a generation (all objects in a generation are stored in a linked list). The more objects that exist, the longer it takes to perform a collection. In RelStorage 2, storing a value in the cache required creating several objects, and the Python garbage collector would have to examine these. The RelStorage 3 cache does not create objects that the garbage collector needs to traverse. Similar remarks hold for PyPy. |
| [3] | That change was support for SQLite, which requires the entire "transaction" table to be quoted. Amusingly, "transaction" is a word reserved by the SQL standard, while "empty" is not. |
| [4] | With the exception of PostgreSQL using one thread for 20 objects. The large error bar indicates an outlier event. We're working with relatively small sample sizes, so that throws things off. |
| [5] | RelStorage 2 implemented some of its cache functions using native code called by CFFI. When CFFI calls native code, Python's GIL is dropped, allowing other threads to run (as long as they weren't trying to use the cache, which used Python locks for thread safety). In contrast, RelStorage 3 uses a thin layer of cython to call into C++ and does not drop the GIL—it depends on the GIL for thread safety. The substantial speed improvement should outweigh the loss of the tiny window where the GIL was dropped. |
| [6] |
We don't have that much granular control over the PostgreSQL driver (psycopg2). With MySQL (mysqlclient), on a connection-by-connection basis we can control if a particular query is going to yield to gevent or block. But with psycopg2, whether it yields or not is global to the entire process. The reverse is that psycopg2 actually gives us exactly the same control as a gevent socket (yield each time any read/write would block), whereas in mysqlclient we can only wait for the first packet to arrive/go, after that it blocks for the duration (server-side cursors give us a bit more control, allowing yields between fetching groups of rows). |